Data Inconsistency and wsrep_on variable on MySQL/MariaDB Galera Cluster
To perform rolling upgrade or schema migration you must spend some time on preparation and testing because just slight mistake or oversight can cause cluster freeze and significant application downtime. There are various tools and techniques explaining how to perform such tasks and I would recommend to test them out and choose the one which is the best for your task.
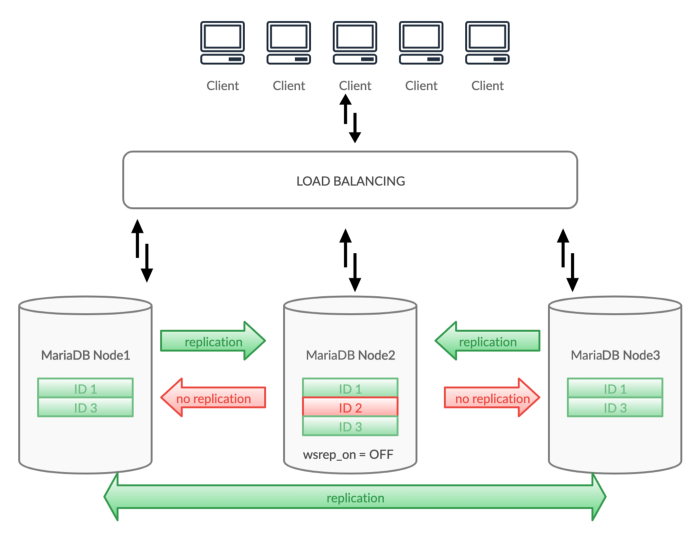
To mitigate effect on the whole cluster while performing sensitive tasks like schema changes some DBA's set " wsrep_on=OFF" variable without thinking about possible consequences.
One of the biggest advantages of Galera Cluster over standard replication is plug-in for InnoDB which provides exact data copies between nodes using certification-based replication. You don't have to worry about on which node you will write or how to add/remove a node from the cluster. It is very convenient.
Although you can perform checks to be sure that you have exact data copies between nodes, as you would often do for standard replicas, it is very rare that anybody does that.
This is why data inconsistency in Galera Cluster can go unnoticed for months or years or you might never find out that nodes in your cluster don't have exact data.
Test Environment
MariaDB Galera Cluster 10.4.6 — wsrep_provider_version=26.4.2(r4498)
Ubuntu 18.04.1
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`text` varchar(20) DEFAULT NULL,
`modified` timestamp NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp(),
PRIMARY KEY (`id`),
KEY `modified` (`modified`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
WSREP_ON variable
This is Global/Session-based variable for enabling/disabling wsrep replication.
It can be useful to disable cluster replication when performing an upgrade or schema changes but you have to be very careful when using it.
Imagine we have to perform some schema changes on the live "Node2" server.
As "wsrep_on" is a dynamic variable we can alter it without node restart or affecting a running application.
MariaDB Node2>set global wsrep_on=OFF;
While we have disabled replication on Node2 some workload is happening on the whole cluster.
MariaDB Node1>insert into t1(id,text) values (1,@@hostname);
Query OK, 1 row affected (0.013 sec)
MariaDB Node1>commit;
Query OK, 0 rows affected (0.000 sec)
MariaDB Node3>insert into t1(id,text) values (3,@@hostname);
Query OK, 1 row affected (0.012 sec)
MariaDB Node3>commit;
Query OK, 0 rows affected (0.000 sec)
MariaDB Node2>insert into t1(id,text) values (2,@@hostname);
Query OK, 1 row affected (0.010 sec)
MariaDB Node2>commit;
Query OK, 0 rows affected (0.000 sec)
Data Inconsistency
What if we query the T1 table:
MariaDB Node1>select * from t1;
+ — — + — — — — -+ — — — — — — — — — — -+
| id | text | modified |
+ — — + — — — — -+ — — — — — — — — — — -+
| 1 | marija1 | 2019–07–27 23:59:02 |
| 3 | marija3 | 2019–07–27 23:59:11 |
+ — — + — — — — -+ — — — — — — — — — — -+
2 rows in set (0.001 sec)
MariaDB Node3>select * from t1;
+ — — + — — — — -+ — — — — — — — — — — -+
| id | text | modified |
+ — — + — — — — -+ — — — — — — — — — — -+
| 1 | marija1 | 2019–07–27 23:59:02 |
| 3 | marija3 | 2019–07–27 23:59:11 |
+ — — + — — — — -+ — — — — — — — — — — -+
2 rows in set (0.008 sec)
MariaDB Node2>select * from t1;
+ — — + — — — — -+ — — — — — — — — — — -+
| id | text | modified |
+ — — + — — — — -+ — — — — — — — — — — -+
| 1 | marija1 | 2019–07–27 23:59:02 |
| 𝟐 | 𝐦𝐚𝐫𝐢𝐣𝐚𝟐 | 𝟐𝟎𝟏𝟗–𝟎𝟕–𝟐𝟖 𝟎𝟎:𝟎𝟏:𝟒𝟐 |
| 3 | marija3 | 2019–07–27 23:59:11 |
+ — — + — — — — -+ — — — — — — — — — — -+
3 rows in set (0.001 sec)

Notice that we have one extra row on "Node2", an error that is very hard to notice.
When we change back wsrep_on to ON no error is received and all nodes in the cluster are acting as everything is fine and we have a healthy cluster.
Recovering Inconsistent Database
But not everything is lost and cluster could recover automatically from data inconsistency.
Galera Cluster 4 has strict inconsistency policy — cluster runs inconsistency voting protocol and reacts accordingly to detected inconsistency.
In this case, if we are very lucky, a transaction affecting the problematic row will happen.
Node2 > update t1 set text=concat(text,’_updated’) where id>1;
ERROR 2013 (HY000): Lost connection to MySQL server during query
Problem is found on Node2 and Node2 is immediately aborted — dropped out from the cluster.
Jul 28 00:32:26 marija2 systemd[1]: mariadb.service: Main process exited, code=dumped, status=6/ABRT
Jul 28 00:32:26 marija2 systemd[1]: mariadb.service: Failed with result ‘core-dump’.
Jul 28 00:32:31 marija2 systemd[1]: mariadb.service: Service hold-off time over, scheduling restart.
Jul 28 00:32:31 marija2 systemd[1]: mariadb.service: Scheduled restart job, restart counter is at 6.
To resolve data inconsistency Galera Cluster immediately runs State Snapshot Transfer (SST) and recreates node from a full data copy.

Galera Aware Load Balancer
If you are using Galera aware load balancer like ProxySQL node with disabled cluster replication will be automatically excluded from rotation. Transactions will be redirected to avoid possible data inconsistencies.
Lessons Learned
Be very careful when using "wsrep_on=ON" variable on a GLOBAL scale, either setting a global variable or starting node with modified variable.
If you plan to use it make sure you don't have client transactions running on the node.
Use Galera aware SQL proxy for incoming traffic from MySQL clients. Don't connect to cluster nodes directly.
You must be 100% confident in what you are doing or avoid touching wsrep_on variable because mistakes can be very expensive.
Remember — the biggest problem for Galera Cluster is data inconsistency.